
The digital world is full of data. Every interaction point between businesses, systems, or applications there is new data that is updated or recorded. Companies use this data to derive inference using analytics. The data can be stored in various ways depending on the use and analytical tools used to derive insights. The most common ways to store data are in a flat file or a relational database.
What is a Flat file?
A flat file is a form of data storage where you can store linear data. We could store one record per line in the flat file table. The different columns can be separated or delimited by comma or tab. We can say that a flat file has the simplest, easy to create, inexpensive storage structure for data.
We can consider a spreadsheet or a simple table data as one of the easiest relatable examples of the Flat File. Every column of a Flat file will have a specific data type allocated to it. Here is a sample to explain the flat file model.
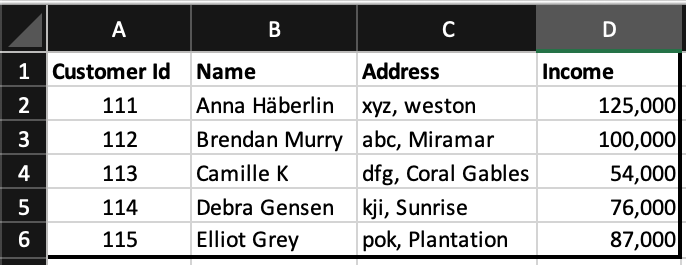
What is a Relational Database?
As the name suggests, the relational database uses the relation between multiple tables to derive relation and bring intelligent data by cross-referencing records between them, utilizing the relationship between the data elements we reduce the redundancy of data and storage size.
The relationship of different tables is stored in the schema of the relational database and can be represented by an Entity Relationship Diagram. Though it takes some time and skills to set up a relational database, it has advantages of cost and management on large, growing data.
For example, if you have to manage a Customer data in your order summary, you can use Customer Id as reference to its name and address and refer whenever you need it thus you do not have to manage the entire name and address of the customer every time you are managing a record. This is how the relational database has a considerable advantage over Flat File.
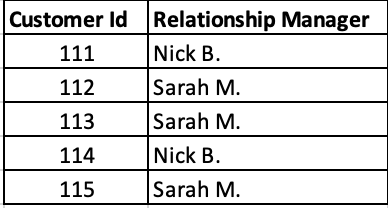
Database Management System
With the ever-growing need to manage a different variety of data, the database management system has also evolved from being able to serve with few megabytes of data to terabytes of data. Ease of accessibility and ability to perform analytics on huge data sets have given rise to Big Data Management system. Here is a graph of how technology has evolved.

Image courtesy: https://www.analyticsvidhya.com/blog/2014/11/types-databases-evolution/
Conclusion:
We can say today we have the availability of a variety of data storage systems to suit our needs. Each database has its own advantage and disadvantage. We should always consider our business needs to pick and choose which fit our Use Case.
The referential or non-referential database does not matter for analytics as, in the end, we infer data out of a normalized (flat) inquiry of the data. It only matters for ease of use, to have clean data, and to store everything in the most efficient way.